
The term Big Data has created a lot of hype already in the business world. Chief managers know that their marketing strategies are most likely to yield successful results when planned around big data analytics. For simple reasons, use of big data analytics helps improve business intelligence, boost lead generation efforts, provide crm implementation services to customers and turn them into loyal ones. However, it’s a challenging task to make sense of vast amounts of data that exists in multi-structured formats like images, videos, weblogs, sensor data, etc.
In order to store, process and analyze terabytes and even petabytes of such information, one needs to put into use big data frameworks. In this blog, I am offering an insight and analogy between two such very popular big data technologies - Apache Hadoop and Apache Spark.
Let’s First Understand What Hadoop and Spark are?
Hadoop: Hadoop, an Apache.org. Project, was the first big data framework to become popular in the open source community. Being both a software library and a big data framework, Hadoop paves the way for distributed storage and processing of large datasets across computer clusters using simple programming models. Hadoop is a framework composed of modules that allow automated handling of common hardware failure occurrences.
The four primary modules that comprise Hadoop’s core are:
-
Hadoop Common: The collection of common utilities and libraries that support other Hadoop modules.
-
Hadoop Distributed File System(HDFS): The primary storage system used by Hadoop applications.
-
Hadoop MapReduce: A software framework to process huge piles of data.
-
Hadoop YARN (Yet Another Resource Negotiator): A cluster management technology.
Hadoop is a file system with a two-stage disk-based compute framework MapReduce and a resource manager YARN. Apart from Hadoop’s core modules, there are several others in existence as well, including Hive, Pig, Ambari, Avro, Oozie, Sqoop and Flume. These modules are also well capable of working with big data applications and processing large data sets.
The main motive behind designing Hadoop was to look through billions of pages and collect their information into a database. And, that gave birth to Hadoop’s HDFS and its distributed processing engine, MapReduce. Hadoop is a great help for companies that have no effective solution to deal with large and complex datasets in a reasonable amount of time.
Apache Spark: Spark, also an open-source framework for performing general data analytics on distributed computing cluster, was originally designed at the University of California, and later donated to the Apache Software Foundation. Spark’s real-time data processing capability provides it a substantial lead over Hadoop’s MapReduce.
Spark is a multi-stage RAM-capable compute framework with libraries for machine learning, interactive queries and graph analytics. It can run on a Hadoop cluster with YARN but also Mesos or in standalone mode. Apples and oranges, really. An interesting point to note here is that Spark is devoid of its own distributed filesystem. So, for distributed storage, it has to either use HDFS or other alternatives, such as MapR File System, Cassandra, OpenStack Swift, Amazon S3, Kudu, etc.
Now that we have caught a glimpse of Hadoop and Spark, it’s time to talk about different types of data processing they perform.
What are Different Types of Data Processing?
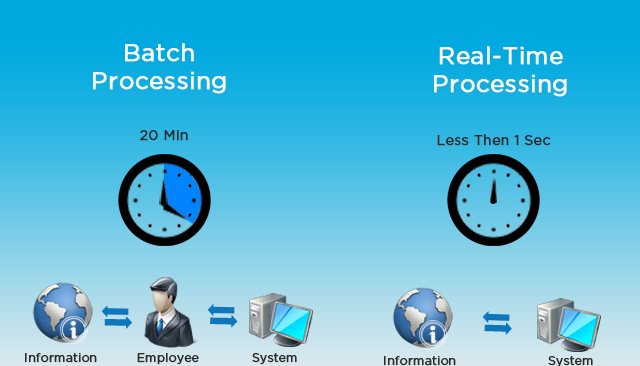
Image source: LinkedIn
There are three types of data processing: Batch Processing, Stream Processing and Hybrid Processing.
Batch Processing: Batch processing has been pivotal to big data world for years now. The simplest way we can define batch processing is operating over high volumes of data collected over a period of time. Since data is first collected, entered and then processed, results are produced at a later stage. Although batch data processing is an efficient way of processing large, static datasets, the time taken to return the result is long as it happens only after the computation is complete.
Nevertheless, batch processing is the best for holistic treatment of datasets. For example, when access to a complete data set is required, like calculating totals and averages, there is no data processing more suitable than batch processing.
Click here to learn more about batch processing
Stream processing: Stream processing has become the current trend in the big data world. The modern business era is about speed and real-time information, which is what steam processing is the most suitable for. Since batch processing does not allow businesses to react to changing business conditions in real time, stream processing has witnessed a rapid rise in demand in past few years.
Although stream processing systems can also handle vast amounts of data, they operate over one or micro batches at a time. According to Mike Gualtieri, an analyst at Forrester Research, “With traditional analytics you gather information, store it and do analytics on it later. We call that at-rest analytics.” However, streaming technologies allow analysis of a series of events that have just happened. “It could be a piece of farm equipment that has a lot of sensors on it emitting data on temperature and pressure. You want to analyze that in real-time to see if there is a risk of the engine blowing up.”
Click here to take a deep-dive into stream processing of big data
Hybrid Processing: Hybrid processing is nothing, but the capability of a processing system to perform both batch processing and stream processing.
Comparison Between Apache Hadoop and Apache Spark
Data Processing
Hadoop: Apache Hadoop provides batch processing. In fact, Hadoop was the first framework that created ripples in the open-source community. Google’s revelation about how they were working with vasts amounts of data helped Hadoop developers a great deal in creating new algorithms and component stack to improve access to large scale batch processing.
MapReduce is Hadoop's native batch processing engine. Several components or layers (like YARN, HDFS etc) in modern versions of Hadoop allow easy processing of batch data. Since MapReduce is about permanent storage, it stores data on disk, which means it can handle large datasets. MapReduce is scalable and has proved its efficacy to deal with tens of thousands of nodes. However, Hadoop’s data processing is slow as MapReduce operates in various sequential steps.

Image source: zData Inc
Spark: Apache Spark is a good fit for both batch processing and stream processing, meaning it’s a hybrid processing framework. Spark speeds up batch processing via in-memory computation and processing optimization. It’s a nice alternative for streaming workloads, interactive queries, and machine-based learning. Spark can also work with Hadoop and its modules. The real-time data processing capability makes Spark a top choice for big data analytics.
Resilient Distributed Dataset (RDD) allows Spark to transparently store data on memory, and send to disk only what’s important or needed. As a result, a lot of time that is spent on the disc read and write is saved.
Ease of Use
Spark is easier to use than Hadoop as it comes with user-friendly APIs for Scala (its native language), Java, Python, and Spark SQL. Hadoop, on the other hand, is written in Java, difficult to program and requires abstractions. Since Spark provides a way to perform streaming, batch processing and machine learning in the same cluster, users find it easy to simplify their infrastructure for data processing.
An interactive REPL (Read–eval–print loop) allows Spark users to get instant feedback for the commands. Although there is no interactive mode available with Hadoop MapReduce, tools like Pig and Hive make it easier for adopters to work with it.
Graph Processing
Hadoop: Most processing algorithms, like PageRank, perform multiple iterations over the same data. MapReduce reads data from the disk and after a particular iteration, it sends results to the HDFS and then again reads the data from the HDFS for next iteration. Such a process increases latency and makes graph processing slow.
In order to evaluate the score of a particular node, message passing needs to contain scores of neighboring nodes. And, these computations require messages from it neighbors, but MapReduce doesn’t have any mechanism for that. Although there are fast and scalable tools, like Pregel and GraphLab, for efficient graph processing algorithms, they are not suitable for complex multi-stage algorithms.
Spark: Spark comes with a graph computation library called GraphX to make things simple. In-memory computation coupled with in-built graph support allows the algorithm to perform much better than traditional MapReduce programs. Netty and Akka make it possible for Spark to distribute messages throughout the executors.
Fault Tolerance
Hadoop: Hadoop achieves fault tolerance through replication. MapReduce uses TaskTracker and JobTracker for fault tolerance. However, TaskTracker and JobTracker have been replaced in second version of MapReduce by Node Manager and ResourceManager/ApplicationMaster, respectively.
Spark: Spark uses RDD and various data storage models for fault tolerance by minimizing network I/O. In the event of partition loss of an RDD, the RDD rebuilds that partition through the information it already has. So, Spark does not use the replication concept for fault tolerance.
Security
Hadoop MapReduce has better security features than Spark. Hadoop supports Kerberos authentication, which is a good security feature but difficult to manage. Hadoop MapReduce can also integrate with Hadoop security projects, like Knox Gateway and Sentry. Third party vendors also allow organizations to use Active Directory Kerberos and LDAP for authentication. Hadoop’s Distributed File System is compatible with access control lists (ACLs) and a traditional file permissions model.
Spark’s security is currently in its infancy, offering only authentication support through shared secret (password authentication). However, organizations can run Spark on HDFS to take advantage of HDFS ACLs and file-level permissions.
Costs
Both Hadoop and Spark are open-source projects, therefore come for free. However, Spark uses large amounts of RAM to run everything in memory, and RAM is more expensive than harddisks. Hadoop is disk-bound, so saves the costs of buying expensive RAM, but requires more systems to distribute the disk I/O over multiple systems.
As far as costs are concerned, organizations need to look at their requirements. If it’s about processing large amounts of big data, Hadoop will be cheaper since hard disk space comes at a much lower rate than memory space.
Compatibility
Both Hadoop and Spark are compatible with each other. Spark can integrate with all the data sources and file formats that are supported by Hadoop. So, it’s not wrong to say that Spark’s compatibility to data types and data sources is similar to that of Hadoop MapReduce.
Both Hadoop and Spark are scalable. One may think of Spark as a better choice than Hadoop. However, MapReduce turns out to be a good choice for businesses that need huge datasets brought under control by commodity systems. Both frameworks are good in their own sense. Hadoop has its own file system that Spark lacks. And, Spark provides a way for real-time analytics that Hadoop does not posses.






Comments