
Data collection and analytics have always been crucial to chief business managers’ capability of making right business decisions. But unlike past, databases now have data with high volume, velocity, and veracity. Going by a big data infographic contributed by Ben Walker of Voucher Cloud in 2015, around 2.5 quintillion Bytes of data is created every day. The amount is good enough to fill 10 million Blu-ray discs.
Given the gigantic amount of data existing in databases nowadays, data industry coined a new term for it - Big Data. Big Data is basically large volumes of information present in databases in structured, semi-structured and unstructured form.
Image source:
A lot of hype has already been created around big data analytics as it opens new avenues for business managers to boost sales by targeting or retargeting right customers. Big data analytics helps understand what customers want to buy and what they don’t like about your products or services. Therefore, you can figure out a quick fix and improve the brand value of your business. Besides, you can provide personalized experiences and add more numbers to the list of loyal customers.
However, an important point to note here is that making sense of big data is a very challenging task. That said, one needs to put into use an analytics tool to make sense of big data and turn it into significant business value. Let’s discuss 7 tools business managers can use to work with big data for successful analytics.
7 Tools for Big Data Analytics
#1 Hadoop

Apache Hadoop is an open-source software framework that facilitates distributed processing of very large data sets across hundreds of inexpensive servers that operate in parallel. It’s been quite a time business have been using Hadoop to sort and analyze big data. Hadoop uses simple programming models to ensure distributed processing of large data sets and making them available on local machines.
#2 Storm
Storm, another product from Apache, is a real-time big data-processing system. Storm is also open source and can be utilized by both small and big businesses. It is fault tolerant and goes well with any programming language. Storm is capable of performing data processing even if any of the connected nodes in the cluster die or messages are lost. Other tasks that Storm can perform is distributed RPC and online machine learning. Storm is a good choice for big data analytics as it integrates with existing technologies, which makes processing of big data much easier.
#3 Hadoop MapReduce
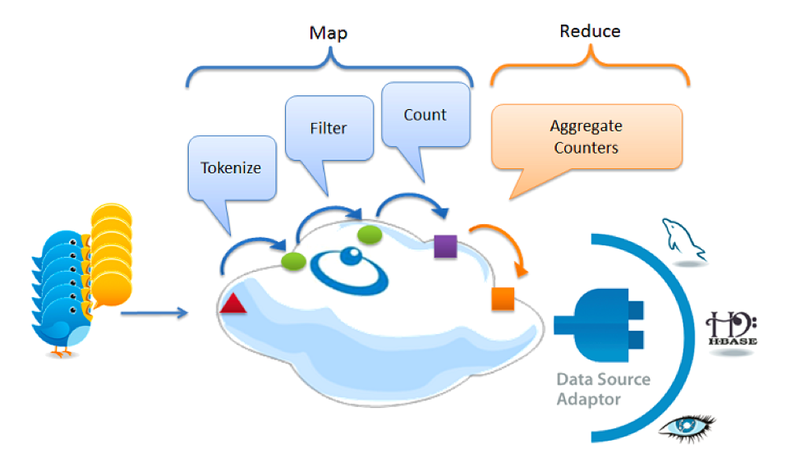
Image source: gigaspaces.com
Hadoop MapReduce is a programming model and software framework for writing data processing apps. Originally developed by Google, MapReduce enables quick processing of vast amounts of data in parallel on large clusters of compute nodes.
The MapReduce framework has two types of key functions. First, the map function which separates out data to be processed, and second, the reduce function which performs data analysis. As MapReduce involves two-stage processing, it’s believed that a large number of varied data analysis questions can also be answered with it. You can also easily integrate your Hadoop environment with other services such as AWS data integration services.
#4 Cassandra
Apache Cassandra is highly scalable NoSQL database. It is capable of monitoring large sets of data spread across large clusters of commodity servers and the cloud. Cassandra was initially developed at Facebook out of a need for a database to power their Inbox Search. The big data tool is now widely used by many famous enterprises with large, active datasets, including Netflix, eBay, Twitter and Reddit.=
#5 OpenRefine
OpenRefine (formerly GoogleRefine) is an open source powerful tool that is meant to work with messy data. The tool allows quick cleaning of huge sets of messy data. Then, it transforms the data into useable format for further analyses. Even non technical users can integrate OpenRefine into their data workflow at ease. OpenRefine also enables to create instantaneous links between datasets.
#6 Rapidminer
Rapidminer is an open source tool that is capable of handling unstructured data, like text files, web traffic logs, and even images. The tool is basically a data science platform that relies on visual programming for operation. With Rapidminer comes functions which include manipulation, analysis, modeling, creation of models, and fast integration in business processes. Rapidminer has become popular among data scientists as it offers a full suite of tools to help make sense of data and convert it to valuable business insights.
#7 MongoDB

Image courtesy: devGeeK
MongoDB is an open source and widely used database for high performance, high availability, and easy scalability. It is classified as a NoSQL database. MongoDB’s distributed key value store, MapReduce calculation capability and document-oriented NoSQL features make it a popular database for big data processing. MongoDB is well suited for programming languages like JavaScript, Ruby and Python. MongoDB is easy to install, configure, maintain and use.
Big data analytics has become the need of the hour for business managers to make smarter business moves and yield higher profits. However, without a big data analytics tool, it’s very difficult to uncover hidden patterns, correlations and other insights to get a competitive advantage and take your business to new heights. With this, I am wrapping up this blog, hoping it helps you choose a big data analytics tool that suits your business the best.






Comments